Membrane at Entangled Realities – Leben mit künstlicher Intelligenz im HeK (Haus der elektronischen Künste Basel), 08.05.-11.08.2019. Foto: Sabine Himmlsbach
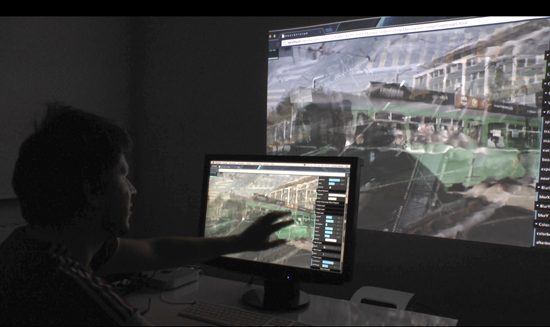
Ausstellung Entangled Realities Foto: Franz WamhofAusstellung Entangled Realities Foto: Franz WamhofView into the restaurant area of the museumMembrane with interface at Kunstverein Tiergarten Galerie Nord. Operator: Sandra Anhalt
Membrane is an art installation which was produced as the main work of a similarly named exhibition at the Kunstverein Tiergarten in Berlin early 2019. It builds on a series of generative video installations with real time video input. Membrane allows the viewer to interact directly with the generation of the image by a neural network, here the so-called TGAN algorithm. An interface allows to experience the ‘imagination’ of the computer, guiding the visitor according to curiosity and personal preferences.
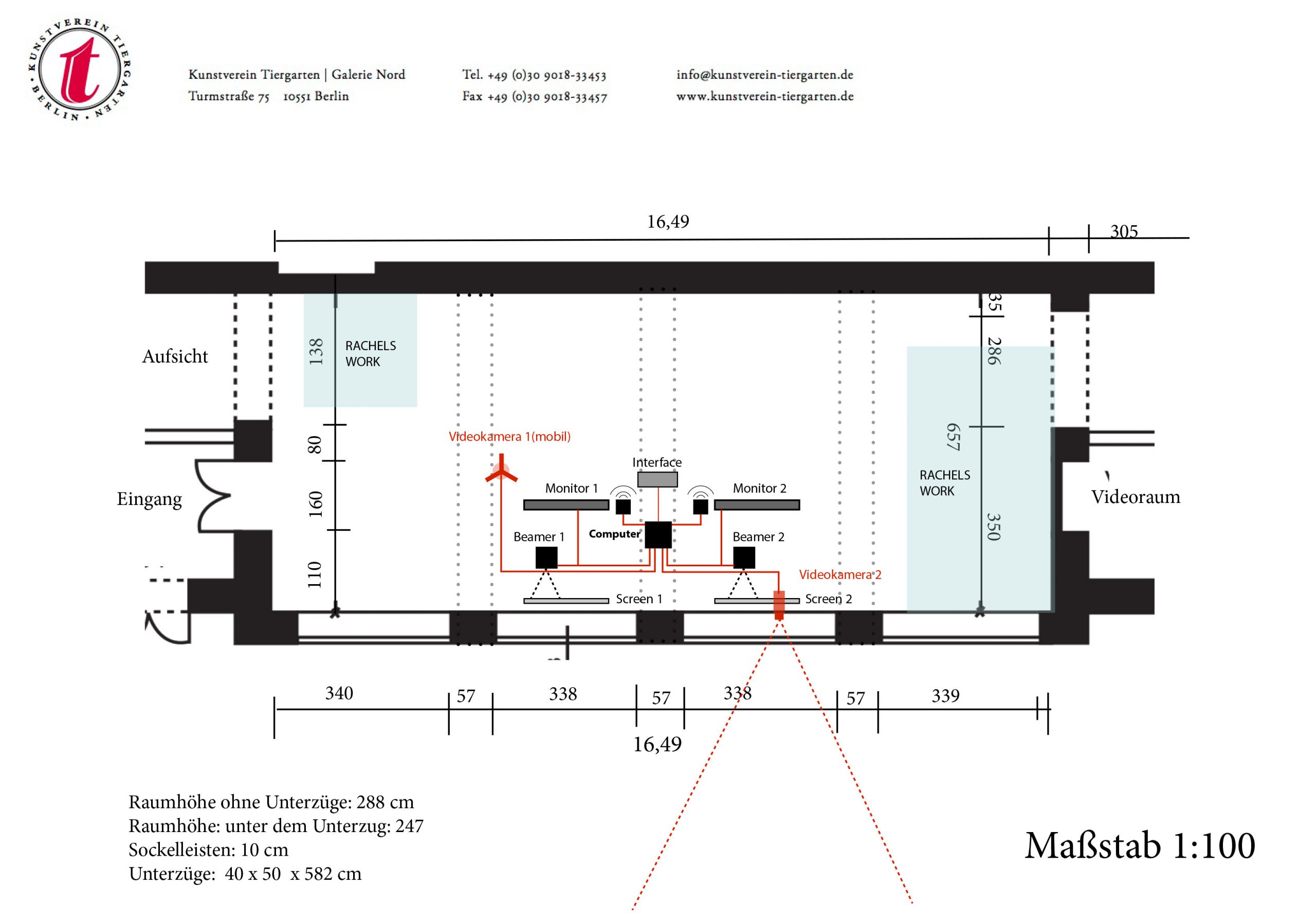
The images of Membrane are derived from a static video camera observing a street scene in Berlin. A second camera is positioned in the exhibition space and can be moved around at will. Two screens are showning both scenes in realtime.
In my earlier artistic experiments within this context we considered each pixel of a video data stream as an operational unit. One pixel learns from colour fragments during the running time of the programme and delivers a colour which can be considered as the sum of all colours during the running time of the camera. This simple method of memory creates something fundamentally new: a recording of patterns of movement at a certain location.
Diagrammatic drawing of data flow
On a technical level, Membrane not only controls pixels or clear cut details of an image, but image ‘features’ which are learnt, remembered and reassembled. With regards to the example of colour: we choose features but their characteristics are delegated to an algorithm. TGANs (Temporal Generative Adversarial Nets) implement ‘unsupervised learning’ through the opposing feedback effect of two subnetworks: a generator produces short sequences of images and a discriminator evaluates the artificially produced footage. The algorithm has been specifically designed to produce representations of uncategorised video data and – with the help of it – to produce new image sequences. (Temporal Generative Adversarial Nets).
We extend the TGAN algorithm by adding a wavelet analysis which allows us to interact with image features as opposed to only pixels from the start. Thus, our algorithm allows us to ‘invent’ images in a more radical manner than classical machine learning would allow.
In practical terms, the algorithm speculates on the the basis of its learning and develops its own, self organised temporality. However, this does not happen without an element of control: feature classes from a selected data set of videos are chosen as target values. In our case, the dataset consists of footage from street views of other cities from around the world, taken while travelling.
The concept behind this strategy is not to adapt our visual experience in Berlin to global urban aesthetics but rather to fathom the specificity and to invent by associations. These associations can be localised, varied and manipulated within the reference dataset. Furthermore, our modified TGAN algorithm will generate numerous possibilities to perform dynamic learning on both short and long timescales and ultimately to be controlled by the user/ visitor. The installation itself allows the manipulation of video footage from a unchanged street view to purely abstract images, based on the found features of the footage. The artwork wants to answer the question of how we want to alter realistic depictions. What are the distortions of ‘reality’ we are drawn to? Which fictions are lying behind these ‘aberrations’? Which aspects of the seen do we neglect? Where do we go with such shifts in image content and what will be the perceived experience at the centre of artistic expression?
From an artistic point of view, the question now arises, how can something original and new be created with algorithms? This is the question behind the software design of Membrane. Unlike other AI-Artworks we don’t want to identify something specific within the video footage, but rather we are interested in how people perceive the scenes. That is why our machines look at smaller, formal image elements and features which intrinsic values we want to reveal and strengthen. We want to expose the visitors to intentionally vague features: edges, lines, colours, geometrical primitives, movement. Here, instead of imitating a human way of seeing and understanding, we reveal the machine’s way to capture, interpret and manipulate visual input. Interestingly, the resulting images resemble pictorial developments of classical modernism (progressing abstraction on the basis of formal aspects) and repeat artistic styles like Pointilism, Cubism and Tachism in a uniquely unintentional way. These styles fragmented the perceived as part of the pictorial transformation into individual sensory impressions. Motifs are now becoming features of previously processed items and are successively losing their relation to reality. At the same time, we question whether these fragmentations of cognition are proceeding in an arbitrary way or whether there may be other concepts of abstraction and imagery ahead of us?
From a cultural perspective, there are two questions remaining: – How can one take decisions within those aesthetic areas of action (parameter spaces)? – Can the shift of the perspective from analysis to fiction help to asses our analytical procedures in a different way – understanding them as normative examples of our societal fictions serving predominantly as a self-reinforcement of present structures?
Thus unbiased artistic navigation within the excess/surplus of normative options of actions might become a warrantor for novelty and the unseen.
Chromatographic Orchestra is an artistic installation which allows a visitor to direct a software framework with an EEG device. In an exhibition environment with semi-transparent video screens a visitor is sitting in an armchair and learns to navigate unconsciously – with his/her brain waves the parameter space of our software – Neurovision.
Neurovision interacts with live video footage of the location of the exhibition and its surroundings. By navigating with his/her own brain waves the visitor can define and navigate the degree of abstraction of a generative (machine learning) algorithm, performed on the footage of different, nearby video cameras.
Vizualisation for ideal set-upideal set-up for the installationOur Operator Lisa sitting in front of the screen with a EEG device
The installation refers back to painting techniques in the late 19th and early 20th century, when painting became more an analysis of the perception of a setting then a mere representation of the latter. Impressionism and Cubism were fragmenting the items of observation while the way of representation was given by the nature of the human sensory system.
The installation “chromatographic orchestra” does not apply arbitrary algorithms to the live footage: we developed a software – the Neurovision framework – which mimics the visual system of the human brain. Thus we question whether our algorithms meet the well being of the spectator by anticipating processing steps of our brain.
Artistic Motivation
How much complexity can our senses endure, or rather how could we make endurable what we see and hear? Many communication tools have been developed, to adjust human capabilities to the requirements of the ever more complex city.
Our installation poses the opposite question: How can information emerging from the city be adjusted to the capabilities of the human brain, so processing them is a pleasure to the eye and the mind?
At the core of our installation is the NeuroVision Sandbox, a custom made framework for generative video processing in the browser based on WebGL shaders.
Inside this Sandbox we developed several sketches, culminating in the “Chromatographic Neural Network”, where both optical flow and color information of the scene are processed, inspired by information processing in the human visual system.
We critically assess the effect of our installation on the human sensory system:
Does it enhance our perception of the city in a meaningful way?
Can it and if so – how will it affect the semantic level of visual experience?
Will it create a symbiotic feedback loop with the visitor’s personal way to interpret a scene?
Will it enable alternate states of consciousness? Could it even allow visitors to experience the site in a sub-conscious state of “computer augmented clairvoyance”
Installation
In a location close to the site a single visitor directs a video-presentation on a large screen with a setup we like to call “the Neural Chromatographic Orchestra” (NCO). Our installation uses an EEG-Device (Emotiv NeuroHeadset) that lets visitors interact with a custom neural network. The setup allows visitors to navigate through various levels of abstraction by altering the parameters of the artificial neural net.
With the NCO device, a visitor can select and explore real-time views provided by three cameras – located in public space – with different perspectives on the passer-byes (birds-eye view and close-ups)
The installation is based on the NeuroVision Sandbox used in the development of “transits”. Other than transits, chromatographic ballads uses multi-channel real-time video-input and enables a visitor to interact with irectly via biofeedback with the neural network.
The Neural Chromatographic Orchestra investigates how human perception reacts to the multifaceted visual impressions of public space via an artistic setting. Using an EEG-Device visitors can interact with a self-organizing neural network and explore real-time views of an adjacent hall from several perspectives and at various levels of abstraction.
Biological Motivation
The Chromatographic Neural Network is a GPU-based video processing tool. It was inspired by parallel information processing in the visual system of the human brain. Visual information processing inside the brain is a complex process involving various processing stages.The visual pathway includes the retina, the Lateral Geniculate Nucleus (LGN) and the visual cortex
Low-level visual processing is already active at the various layers of the retina. The Interconnection of neurons between retina layers, and the ability to retain information using storage or delayed feedback, allows for filtering the visual image in the space and time domain.
Both image filters and motion detection can easily be achieved by accumulating input from neurons in a local neighborhood, in a massively parallel way.
Our Chromatographic Neural Network uses this approach to cluster colors and to compute the visual flow (or retina flow ) from a video source. The resulting attraction-vectors and flow-vectors are used to transform the memory retained in the memory layer.
The visual output of the system directly corresponds to the state of the output layer of the neural network. The neural layers of the Chromatographic Neural Network, are connected to form a feedback loop. This giving rise to a kind of homeostatic-system that is structurally coupled to the visual input but develops its own dynamics over time.
The set-up
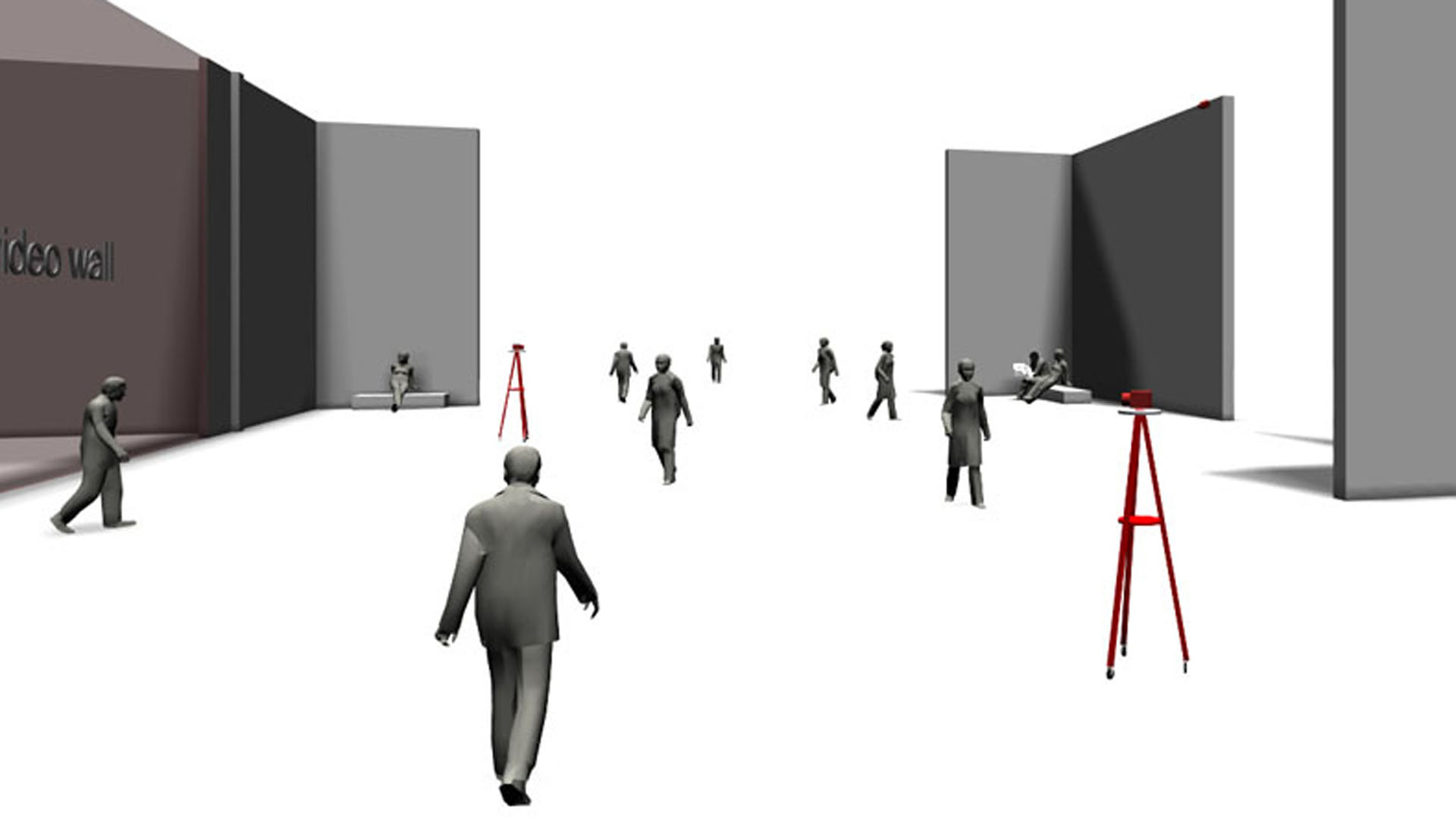
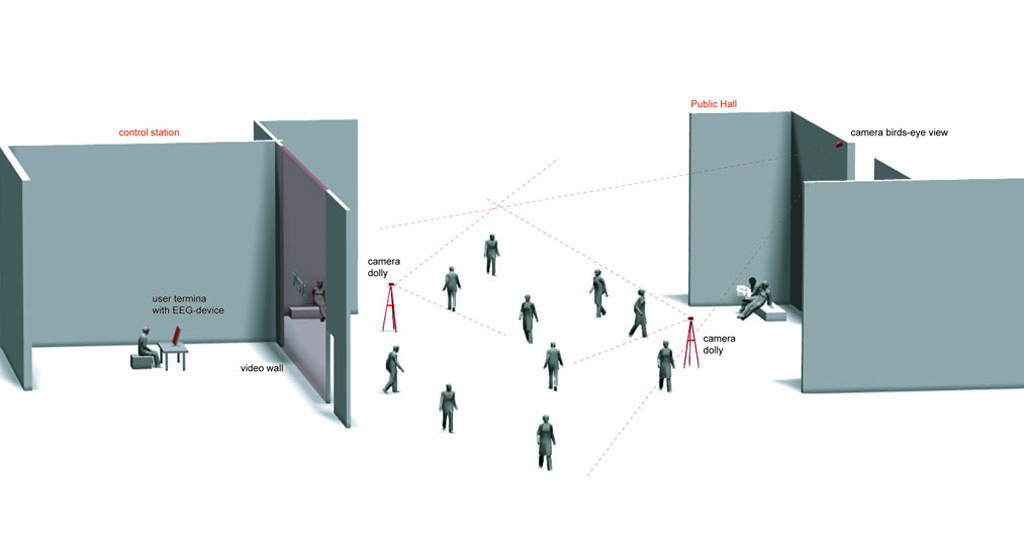
A visitor enters the site – a highly frequented passage, a spacious hall or a public place. Two videocameras, mounted on a tripod, can be moved around at will.
Another camera observes the passer-byes – their transits and gatherings – from an elevated location. The video footage from this site is streamed into a neighboring room – the orchestra chamber of the Neural Chromatographic Orchestra.
Here one can see – in front of a a large video wall a monitor displaying the videos from the adjacent room and the “orchestra pit” – an armchair equipped with a touch device and a neuro-headset. The video wall, showing abstract interpretations of the site itsself, should ideally be visible both from the orchestra pit and from the large hall.
The Orchestra Chamber
Inside the chamber the visitor is seated in a comfortable armchair and an assistant helps her put on and adjust the neuro-headset.
The orchestra chamber should be isolated from the public area as much as possible. A sense of deprivation from outside stimuli allows the visitor to gain control over her own perception and achieve a state of mind similar to meditation or clairvoyance.
The Orchestral Performance
Training Cognitive Control
A performance with the Neural Chromatographic Orchestra starts with a training of up to six mental actions, corresponding to the “push/pull”, “left/right“ and “up/down” mental motions provided by the Emotiv Cognitiv suite. The training typically lasts 10 to 30 minutes.
Playing the Sandbox
After successful training the visitor is asked to sit in front of the NeuroVision Sandbox:
The visitor in the orchestra chamber has three modes of conducting the neural network
either the birds-eye view or one of the cameras that take a pedestrian’s perspective
A graphical user interface lets her switch between different neural networks and control their parameters
A menu lets her choose any of the three cameras as a video source:
the NeuroHeadset allows to navigate the parameter space of the selected neural network
Conducting the Orchestra
Once the visitor feels comfortable conducting the NCO on the small screen, she can perform on the large screen, that is also visible from the outside.
On the public screen sliders are not shown, but the conductor may still use a tablet device to access the graphical user interface.
The current position in parameter spaces is represented by a 3d-cursor or wire-frame box, which is very helpful for making the transition from voluntary conduction moves, to a style of conducting that is more directly informed by immersion and interaction with the output of the Chromatographic Neural Network.
The Chromatographic Neural Network
The flow of information is arranged into several processing layers. To realize memory, each processing layer is in turn implemented as stack of one or more memory layers.This allows us to access the state of a neuron at a previous point in time.
Example
The video layer is made up of two layers, so the system can access the state of any input neuron at the current point in time, and its state in the previous cycle.
Processing Layers
The Video layer
The Video layer contains the input neurons. Each neuron corresponds to a pixel of the video source. The Video layer provides the input for the Flow layer.
The Ghost Layer
The Ghost layer represents a haunting image from the past. It implements the long term memory, that interferes and interacts with the current visual input. It does not change over time, and is provided as additional input to the Flow layer
The Flow layer
The Flow layer accumulates the input from the Video layer and the Ghost layer. Each Neuron aggregates input from its neighborhood in the Video Layer at times (t) and (t-1). The computed 2d vector is directly encoded into the the state of the neuron, creating a flow map.
The Blur layers
The Blur layers are used to blur the flow map. While the computation of visual flow is restricted to a very small neighborhood, the blur layer is needed to spread the flow information to a larger region, since flow can only be detected on the edge of motion.
For efficiency reasons the blur function is split into two layers, performing a vertical and a horizontal blur respectively.
Neuron Processing
The state of each neuron corresponds to an RGB color triplet. Every neuron of the Flow layer gets input from corresponding neurons inside a local neighborhood of the input layers. Each of those input samples corresponds to a single synapse. The vector from the center of the neuron towards the input neuron is referred to as the synapse vector.
Color Attraction
To achieve some kind of color dynamics, colors that are close in color space are supposed to attract each other.
The distance between synapse input and the neuron state in RGB color-space, serves as a weight, which is used to scale the synapse vector. The sum of scaled synapse vectors results in a single color attraction vector.
Color Flow
While color attraction is the result of color similarities or differences in space, color flow is the result of a color changes over time. Rather than calculating the distance of the neuron state to a single synapse input, its temporal derivative is calculated by using input from a neuron and its corresponding memory neuron. This time the sum of scaled synapse vectors results in a flow vector.
Encoding
Both color flow and color attraction vectors are added up and their components are encoded in the flow layer.
Parameters
here are various parameters in each layer controlling the amount and direction of color attraction, color flow, the metrics used for calculating color distances, the neuron neighborhood, etc …
Implementation
All neural computation is performed on the GPU using OpenGL and GLSL shaders. This is the mapping from neural metaphors to OpenGL implementation:
In our implementation both color flow and attraction are integrated into a single level flow map. While this generates interesting local interactions, there is little organization on a global level. The work on Multilevel Turing Patterns as popularized by Jonathan McCabe shows that it is possible to obtain complex and visually interesting self organizing patterns without any kind of video input.
Our future research will combine several layers of flow maps, each operating on a different level of detail. Additional directions include alternate color spaces and distance metrics. In the current model input values are mixed and blurred, resulting in a loss of information over time. We have also been experimenting with entropy-conserving models and are planning to further investigate this direction.
For the work Transits, Ursula Damm filmed the Aeschenplatz in Basel during a period of 24 hours. Every day, thousands of cars, pedestrians and trams pass Basel’s most important traffic junction. “Transits”captures and alienates the recorded stream of motion with an intelligent algorithm that was developed by the artist and her team: It evaluates the audiovisual data and categorizes the patterns of movement and the color schemes. Based on the human memory structure and the visual system, the artificial neuronal network integrated in the software – where every pixel corresponds to one neuron – computes the visual flow. Various perceptional image layers overlap to generate an intriguing visual language in which stationary picture elements compete against the color scene. This begins at night and leads via dawn and noon to dusk; at the same time it is pervaded by arbitrary passersby, by cars, trams and people in the streets. The generative video interprets movements as atmospheres and eventually throws the viewer back to an individual perception of the city.
A detailed description of the algorithms and a further development of a interface for the installation you may find here
Transits has been produced for the exhibition sensing place of the House of Electronic Arts Basel and is part of the collection of the museum.
close-up on the pedestrian level People standing at the platformtop view on the AeschenplatzScreen print
Konzept der Installation: Ursula Damm Vorarbeiten: Matthias Weber Software: Martin Schneider Sound: Maximilian Netter
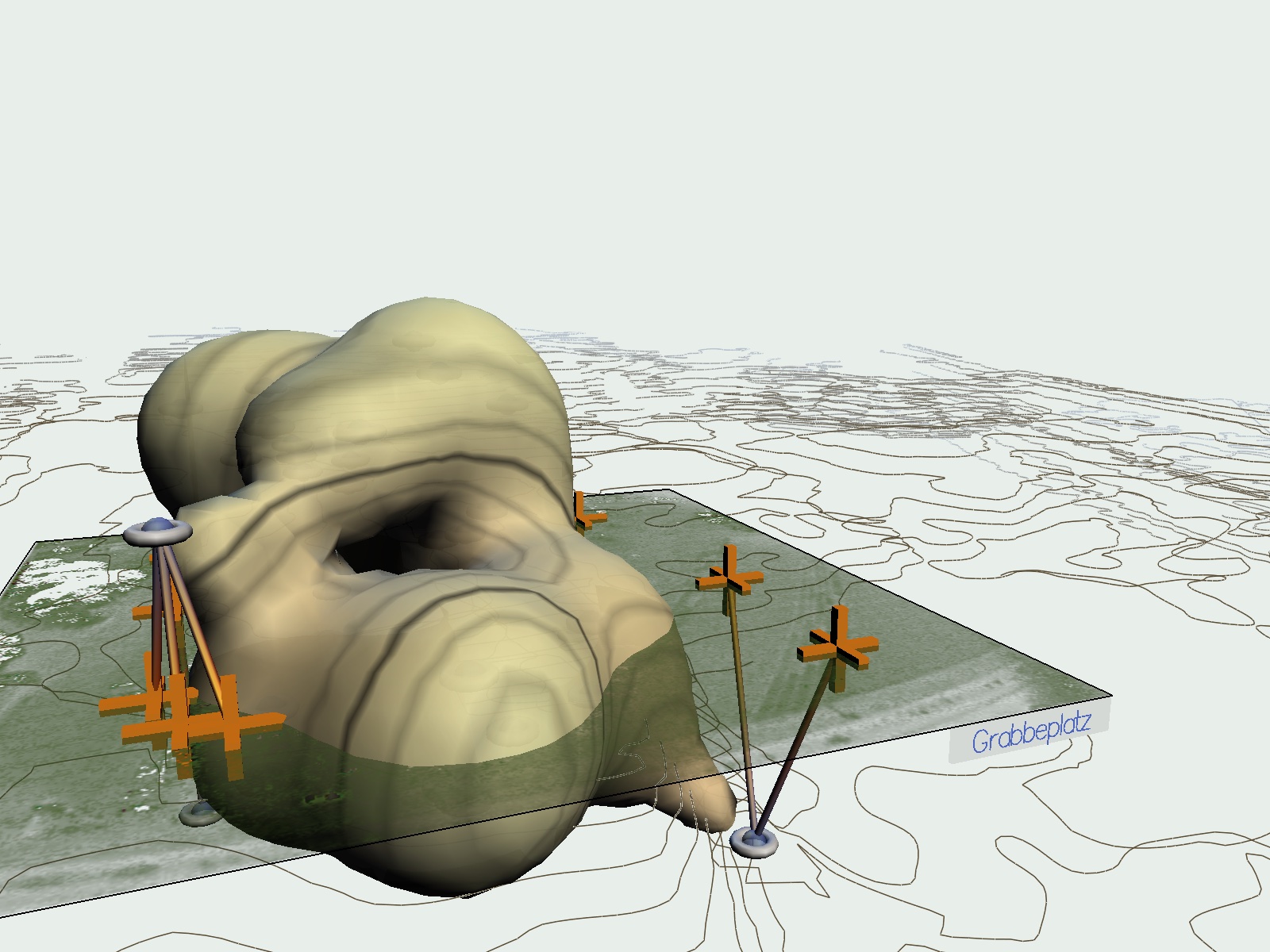
The ‘Zeitraum’ Installation is the most recent “inoutside”-installation in the series of video tracking installations for public spaces.
One perceives a virtual sculpture space-envelope come into being and vanish. This everchanging sculpture is controlled by the occurrences on Grabbeplatz. Like a naturally grown architecture this form is embedded into the contours of the immediate environment of the current location of the viewer. The positions of the people on Grabbeplatz as well as the position of the viewer of the picture are marked with red crosses. Connecting lines point from marked people approximately onto the place of the space-envelope where the people influence the generated form. The installation is made up of nightly projections onto the fountain wall in the passageway of K20. On the roof of the art collection two infrared emitters and an infrared camera are installed. The emitters make up for the missing daylight, so that the camera may pick up the motions on the site. The regular light is an important prerequisite to be able to deduct the motions of the people. This is done by a video tracking program. It is determined where on the site movement takes place by comparing the current video image with a previously taken image of the empty site. The results are then sorted by “blobs”. “Blob” signifies a “Binary Large Object” and denotes a field of non-structured coordinates which moves equably. These animated data-fields are passed on to a graphic- and sound program that calculates the virtual sculpture from the abstracted traces. In this the motion traces are interpreted. As in earlier installations such as “memory space” (2002), “trace pattern II” (1998) or “inoutside I” (1998) and “inoutside II” (1999), the supplied video image is visible on the basis of a video texture so that the people who see this image may recognize themselves in the virtual image. So it becomes clear how the virtual forms, the clouds and arrows are calculated.
The installation deals with architectural and city-planning concepts. A new, different design technique should be attempted, that is aimed at observing the behaviour of people towards architecture. The goal is to depict the city or architecture as a dynamic organism. To show city and people as something collective, something in constant transformation, is what the installation wishes to convey. top
interface/surveillance
The system, the way we used it in the six “inoutside”-installations does not allow for humans to be apprehended in their individuality. It is not about recognizing what makes up each person per surveillance system (for this we humans are still better at than machines), but about perceiving the quality specific to the site and to test it on humans and human behaviour. It’s about the cognition of behavioural patterns, but not about a description of the individual. Moreover the site should be individualized to ascertain its character. top
data processing
With the recording of traces it is so, that the means of computation that is being done in the installation aims to characterise the site, whereby the collecting of the different individual traces becomes essential. The early installations such as “trace pattern II” (1998) are obviously geared towards the interaction amongst the people. The behaviour of the people is recorded, amplified and interpreted: Do they walk close to one another? Are they walking away from each other? Are there “Tracks” – several people walking in step? These observations become part of the interpretation. In the current installation in K20 the space is represented in form of one or multiple bodies. These bodies have entrances and exits, openings and closures, they are being bundled from small units or melt into a large whole or divide. They swell or make holes that enlarge until the bodies dissolve. All these spatial elements are determined by the behaviour of the people. We also map the traces of the visitors of the site according to their different walking-pace and according to their frequency of presence on site onto a mathematical shape-the Isosurface that changes according to behaviour.
The neural network, here the Kohonen map learns through self-organization. This is a method of learning based on the neighbourhood relations of neurons amongst each other. A network is constructed which depicts that which is on the site. Beyond this the classical SOM is modified in order to solve the problem, which is created when the monitored space is a limited area. For at the edge different conditions for calculation apply than in the middle, because the condition of a site is also rooted in its neighbourhood. In the simulation of physical processes one defines the monitored area simply as a torus or a sphere, whereby that, which for example disappears on the right image border, re-appears on the left. This doesn’t make sense for a real site however, which is why we modified the procedure: in the regions with too great an impulse density we let the neurons descend into a second plane that disperses the neurons onto the nearest places that lack neurons. Through this we created a compact cyclical energy evaluation that prevents that only a cluster of the SOM would stay in the middle of the space (see graphics). This would be nothing other than too high of an information density that could provide no information whatsoever (almost a black “data hole”). For me as an artist the application of neural networks in very exciting, because they demand of me that I restrain my artistic and visual desires for the sake of processes which happen with the help of this camera eye – in reality not by the camera but by the people that are the focus of the camera, so by the image of the site. Since the computer-internal data processing apparatus imitates the human perception apparatus, it demands of me that I be concerned about the limits of perception and the possibilities and impossibilities of projection of knowledge.
the isosurface
Isosurface in action
As already mentioned the Grabbeplatz is being reproduced in a virtual image through video texture. It marks the area recorded by the tracking-program, over which the calculations generate an abstract space. The nodes of the SOM form trajectories in this space, nurtured by impulses that refer to speed, direction and length of stay of the passers-by. So the level tracking plane is expanded by another dimension. To visualize the relationships of the nodes not only as points in the room but also in relation to one another, we let an imagined potential energy function reign in the surrounding of every which node. This function is represented as a surface in space. This follows the path of every node and adapts its shape to its current role in the SOM. Such surfaces are called Isosurfaces. They are used to represent the homogeneity of energy states (here: potential energy states) within a continuum. All points of this surface represent an equivocal condition. The potential energy functions- one for each node- overlap or avoid another, amplify or cancel each other out. This event visualizes surfaces which comparable to soapy skin melt into or drip off each other or lose themselves in infinitely minute units. In the arithmetic sum of all the individual potentials lies the key to these surfaces. All points in the room are determined whose potential energy function reach a certain numerical value (decided upon by us). The entirety of these countless points (and thereby the virtual sculpture-shape) appears as a smooth or rugged, porous or compact shape whose constantly moving surface proffers a new way of seeing the development of the SOM. In relation to Grabbeplatz the SOM represents the time-space distortion of the site when it is not seen as a continuous space-shape but as a sum of single “Weltenlinien” (world-lines) of the passers-by, so of the paths of the individual people that cross each other here by chance. The SOM also dissolves time, because paths meet that were temporally offset. In this way the SOM is a memory of personal times that give the Grabbeplatz its individual shape. The ISO-surfaces have the function to discern the areas that are much used and walked upon from those that are scarcely used. Bulges mark the frequent presence of people, holes their absence. The dynamism of the ISO-surfaces follows the dynamism of the accumulation of humans, who, when f. ex. they reach a certain density, fall over and dissolve in turn, to avoid too great of a density. top
The Sound
The sound is a sort of “monitoring” that references the current position of people on the site and that references this position calculated into a long-term organism. Both are graphically represented as positions in the fields which is a visual memory form in a virtual image. The sound will also relate to the current position; a change of position of the viewer consequently changes the sound. When one walks something else is audible on the site than when no one there. On the other hand the sound- and this is the actual quality of noise- transmits information about that, which takes place on the site. And through language it should carry out a categorization. top
architectural context
Architecture as we know it can’t meet the needs of its users, because it is made of properties, of immobile, modern, maybe 70- or 100-year-old buildings. A flexible building is not imaginable yet. But the lifetimes of buildings are diminishing, if one looks at the results of conferences such as “shrinking cities” the trend is towards planning houses that are construct- and de-constructible, that are transferable and flexible in their functions. This is not only my demand, but also the city planner’s. My approach is to get away from the forms of buildings that set statutes as in the past sculptors have done; but that are thought of as a body, in the way that I experience myself; as a sign, that is aesthetically pleasing to me. Of course the new buildings to be designed have to integrate functionally in the devised use zoning plan. But these buildings should observe their surrounding during their use, to determine if they are fulfilling their purpose. The question arises how such a concept could be formulated if it is not only developed based on the idea of one person or a committee of experts, but if it would be submitted to the evaluation by the public. It is not new to claim that architecture has changed with the introduction of the computer, because the methods of design changed with tools or CAD-programs, etc. “Blob architecture” denotes a young architecture that designs more than builds. Most of the time biomorphous building-forms develop in 3D programs. Forms are developed through for example the observation of environmental factors, that become manifest. In this respect one could see the installation at Grabbeplatz as a representative of this form of architecture. The goal of my projects however is not to merely find a different form of buildings, which in turn will only become static monuments, but to test interactive structures , to see which perceptible traces create sensible structures for buildings. “Blob architecture” will have to prove itself by the meaningfulness of the data exploration to be carried out on the blobs. These methods of processing imply a view of humanity that will possibly be the basis of the future architecture.
In the next project of the “inoutside” series the return to real space will be targeted. Today a return to static form and to the sculptural would be too early because we haven’t advanced far enough with the evaluation of the interaction to know what to build, especially as long as the building materials aren’t flexible yet. Also more complex interfaces are necessary that could evaluate a greater spectrum of perceptible human expressions. In the virtual today one is much more flexible and less damaging as long as one leaves it at not building yet and checking the results in the visual and acoustic through users. One can cross over to the formation of real space when architecture is as changeable as the interactive system requires.
The installation “memory of space” links local and geographical dimensions.
It is a cybernetic installation using real time video input and tracking data from video footage. It produced a representation of a public place showing the history of the traces of passengers.
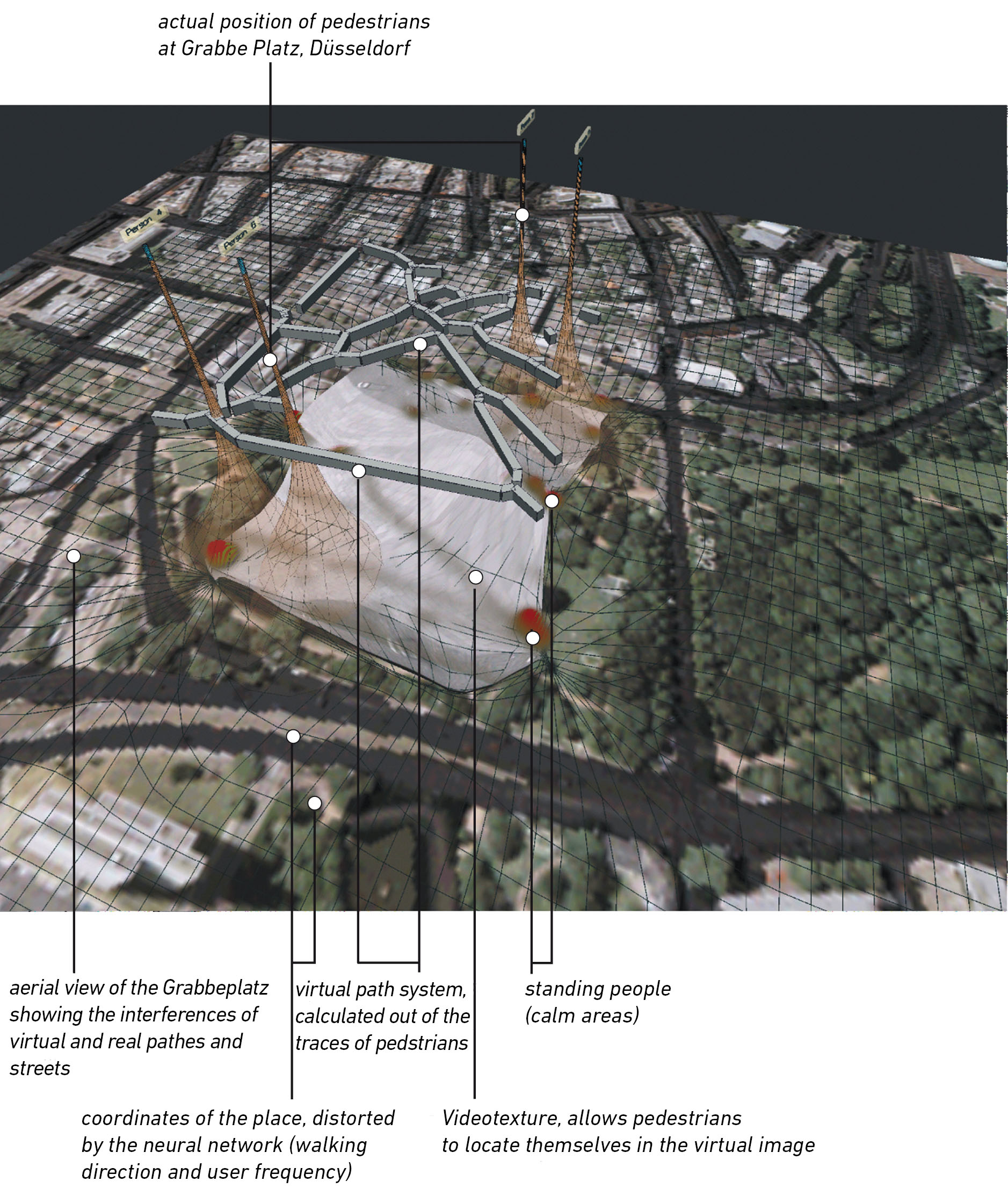
Memory of space is one stage within the framework of the inoutsite project that depicts space in its temporal alterations and explores how individual experiences of „space“ generate the social construct of city. To what extent is the experience of a public space conditioned by me and my (unique) memory – to what degree is it determed by the conventions that result from social intercourse with others and from architectonic/geographic factors? In this case, an large, much-frequented square is monitored by a central camera. The video signals are passed on to two computers which edit the material. The first computer screens an image resulting from an analysis of the movements of people crossing, meeting and/or lingering on the square. Based on the collected movement data of the previous few hours, the second computer calculates an image describing the qualities of the place. The installation „memory of space“ links local and geographical dimensions.
screen print of the software
An aerial view underlying the virtual scene enables an examination of the virtual picture with regard to its potential relationship to large-scale axes. At the base of the virtual picture is a grid-like system of coordinates which, via a self-organizing map (a simple, self-orgaizing neuronal network), is distorted according to the actual usage of the place. At the same time walking speed and direction are applied to the coordinates, pushing them along their direction of travel. A video-texture comprising the video image of the tracked place is mapped onto the coordinate system offering the viewer references to the real place. As a result of this investigation, the monitored place can be divided into „territories“: areas of rest and walking lanes. These lanes are inscribed as a „network of corridors“ (grey lines) onto the distorted (by the movements) reproduction of the square. The remaining spaces – the places where peoples showed a tendancy to dwell (walking speed = 0) – were marked red.






















{kind=link}
{kind=link}